[1] Structure-based ASCII Art
by Xuemiao Xu1, Linling Zhang2, Tien-Tsin Wong3
The Chinese University of Hong Kong
https://www.cse.cuhk.edu.hk/~ttwong/papers/asciiart/asciiart.pdf
Abstract
The wide availability and popularity of text-based communication channels encourage the usage of ASCII art in representing images. Existing tone-based ASCII art generation methods lead to halftone-like results and require high text resolution for display, as higher text resolution offers more tone variety. This paper presents a novel method to generate structure-based ASCII art that is currently mostly created by hand. It approximates the major line structure of the reference image content with the shape of characters. Representing the unlimited image content with the extremely limited shapes and restrictive placement of characters makes this problem challenging. Most existing shape similarity metrics either fail to address the misalignment in real-world scenarios, or are unable to account for the differences in position, orientation and scaling. Our key contribution is a novel alignment-insensitive shape similarity (AISS) metric that tolerates misalignment of shapes while accounting for the differences in position, orientation and scaling. Together with the constrained deformation approach, we formulate the ASCII art generation as an optimization that minimizes shape dissimilarity and deformation. Convincing results and user study are shown to demonstrate its effectiveness.
1 Introduction
ASCII art is a technique of composing pictures with printable text characters [Wikipedia 2009]. It stemmed from the inability of graphical presentation on early computers. Hence text characters are used in place of graphics. Even with the wide availability of digital images and graphics nowadays, ASCII art remains popular due to the enormous growth of text-based communication channels over the Internet and mobile communication networks, such as instant messenger systems, Usenet news, discussion forums, email and short message services (SMS). In addition, ASCII art has already evolved into a popular art form in cyberspace.
ASCII art can be roughly divided into two major styles, tone-based and structure-based. While tone-based ASCII art maintains the intensity distribution of the reference image (Figure 2(b)), structure-based ASCII art captures the major structure of the image content (Figure 2(c)). In general, tone-based ASCII art requires a much higher text resolution to represent the same content than the (a) (b) (c)

structure-based one, as the high text resolution is required for producing sufficient tone variety. On the other hand, structure-based ASCII art utilizes the shape of characters to approximate the image structure (Figure 2(c)), without mechanically following the pixel values. To the extreme, smileys, such as :) and :(, are the simplest examples of structure-based ASCII art.
Existing computational methods can only handle tone-based ASCII art, as its generation can be regarded as a dithering problem with characters [Ulichney ]. O’Grady and Rickard [2008] improved such dithering process by reducing the mismatches bewteen character pixels and the reference image pixels. Nevertheless, high text resolution is still required for a clear depiction. Note that ASCII art gradually loses its stylishness (and approaches to standard halftone images) as its text resolution increases. In addition, as the text screens of mobile devices are limited, the character-saving structure-based ASCII art is more stylish and practical for commercial usage such as text-based advertisement. However, satisfactory structure-based ASCII art is mostly created by hand. The major challenge is the inability to depict the unlimited image content with the limited character shapes and the restrictive placement of characters over the character grid.
To increase the chance of matching appropriate characters, artists tolerate the misalignment between the characters and the reference image structure (Figure 3(b)), and even intelligently deform the reference image (Figure 3(c)). In fact, shape matching in ASCII art application is a general pattern recognition problem. In real-world applications, such as optical character recognition (OCR) and ASCII art, we need a metric to tolerate misalignment and also account for the differences in transformation (translation, orientation and scaling). For instance, in recognizing the characters “o” and “o” the OCR, both scaling and translation count; while in recognizing characters “6” and “9”, the orientation counts. Unfortunately listing shape similarity metrics are either alignment-sensitive [Wang et al. 2004] or transformation-invariant [Mori et al. 2005; Belongie et al. 2002; Arkin et al. 1991], and hence not applicable.
In this paper, we propose a novel method to generate structure-based ASCII art to capture the major structure of the reference image. Inspired by the two matching strategies employed by ASCII artists, our method matches characters based on a novel alignment-insensitive shape similarity metric and allows a constrained deformation of the reference image to increase the chance of character matching. The proposed similarity metric tolerates the misalignment while it accounts for the differences in transformation. Given an input and a target text resolution, we formulate the ASCII art generation as an optimization by minimizing the shape dissimilarity and deformation. We demonstrate its effectiveness by several convincing examples and a user study. Figure 1 shows the result automatically obtained by our method.
2 Related Work
As a culture in the cyberspace, the best references of ASCII art can be found
online. There is collaboratively prepared frequently asked questions (FAQ) for
Usenet newsgroup alt.ascii-art [CJRandall 2003], which keeps track of the
update information and resources related to ASCII art. Other sources of
reference are online tutorials written by individual enthusiasts [Wakenshaw
2000; Crawford 1994; Au 1995]. To produce ASCII art, one can type it using a
standard text editor. It is not as intuitive as painting, however. Enthusiasts
developed interactive painting software [Davis 1986; Gebhard 2009] to allow
users to directly paint the characters via a painting metaphor.
Besides the interactive tools, there are attempts to automatically convert images into ASCII art [Klose and McIntosh 2000; De-Fusco 2007; O’Grady and Rickard 2008]. However, they can only generate tone-based ASCII art, as it can be regarded as a dithering process. The major academic study is in the area of halftoning [Ulichney ; Bayer 1973; Floyd and Steinberg 1974]. O’Grady and Rickard [2008] tailor-made a method for tone-based ASCII art by minimizing the difference between the characters and the reference image in a pixel-by-pixel manner. However, all these methods cannot be extended to generate structure-based ASCII art due to their inability to allow misalignment and deformation. In this paper, we focus on the generation of structure-based ASCII art as it depicts a clearer picture within a smaller text space. Its generation can no longer be regarded as a dithering process. Instead, the shape similarity plays a major role in its generation. 3D collage [Gal et al. 2007] relies on shape matching to aggregate smaller objects to form a large compound one. While transformation invariance is needed during collaging, our character matching must be transformation-aware and with restrictive placement.
3 Overview
An overview of our structure-based ASCII art generation is shown in Figure 4. The basic input is a vector graphics containing only polylines. A raster image can be converted to vector via vectorization. As the limited shapes and restrictive placement of text characters may not be able to represent unlimited image content, ASCII artists slightly deform the input to increase the chance of character matching. So we mimic such deformation during optimization by iteratively adjusting the vertex positions of the input polylines. Given the vector-based line art, we rasterize it and divide the raster image into grid cells. Each cell is then best-matched with a character based on the proposed alignment-insensitive shape similarity metric (Section 4). This completes one iteration of optimization, and the objective value, which composes of the deformation of the vectorized picture (Section 5) and the dissimilarity between the
characters and the deformed picture, can be computed. In the next iteration, we adjust the vertex positions of the vector-based line art with a simulated annealing strategy (detailed in Section 5). Since the line art is changed, the above rasterization-and-AISS-matching process is repeated to obtain a new set of best-matched characters. Such deformation-and-matching process continues until the objective value is minimized.
Before the optimization, we need to prepare the input and the characters. Since character fonts may have varying thicknesses and widths, we simplify the problem by ignoring font thickness (via centerline extraction) and handling only fixed-width character fonts. We further vectorize the characters and represent them with polylines. In order to focus only on the shapes during matching, both the input polylines and the characters are rasterized with the same line thickness (one pixel-width in our system). Note that the characters are only rasterized once as they can be repeatedly used. Before each optimization step, the input polylines are rasterized according to the target text resolution,
, where and are the maximum number of characters along the horizontal and vertical directions respectively. As the aspect ratio of our characters, is fixed, the text resolution can be solely determined by a single variable , as , where and are the width and height of a rasterized character image in the unit of pixels respectively. W and H are the width and height of the input image. Hence, the input polylines are scaled and rasterized to a domain of . Furthermore, since the vector-based input is scalable (W and H can be scaled up or down), users may opt for allowing the system to determine the optimal text resolution by choosing the minimized objective values among results of multiple resolutions, as our objective function is normalized to the text resolution.4 Alignment-Insensitive Shape Similarity
The key to best-match the content in a grid cell with a character is the shape similarity metric. it should tolerate misalignment and, simultaneously, account for the differences in transformation such as, position, orientation and scaling. existing shape similarity metrics can be roughly classified into two extreme categories, alignment-sensitive metrics and transformation-invariant metrics.
Peak signal-to-noise ratio (PSNR) or mean-squared error (MSE), and the well-known structural similarity index (SSIM) [Wang et al. 2004] belong to the former category. Their similarity values drop significantly when two equal images are slightly misaligned during the comparison. On the other hand, the transformation-invariant metrics are designed to be invariant to translation, orientation and scaling. These metrics include shape context descriptor [Mori et al. 2005; Belongie et al. 2002], Fourier descriptor [Zahn and Roskies 1972], skeleton-based shape matching [Sundar et al. 2003; Goh 2008; Torsello and Hancock 2004], curvature-based shape matching [Cohen et al. 1992; Milios 1989], and polygonal shape matching [Arkin et al. 1991]. In our case, the transformation matters. Hence, no existing work is suitable for our application.
In fact, the above metric requirement is not only dedicated to our application, but applicable for real-world applications of pattern recognition and image analysis, such as OCR. For example, Figure 5(a) shows a scanned image ready for OCR. The characters “o”, “o”, “6” and “9” are magnified in Figure 5(b) for better visualization. It is not surprising that the scanned character images (in black) may be slightly misaligned to the ideal characters (in green) no matter how perfect the global registration is. Hence, an alignment insensitive shape similarity metric is essential. Besides the misalignment, the transformation difference has to be accounted for in OCR as well. Characters “o” and “o” have the similar shapes, but are different in position and scaling. Characters “9” and “6” also share the same shape but with a difference in orientation. In other words, the shape information alone is not sufficient for recognition, since position, orientation and scaling have their own special meanings. Therefore, the desired metric must also account for position, orientation, scaling, as well as the shape information.
Misalignment Tolerance Misalignment is, in essence, a small-scale transformation. To tolerate misalignment, a histogram of a log-polar diagram [Mori et al. 2005] is used as the basic building block of our shape descriptor (Figure 6(a)). This log-polar histogram measures the shape feature in a local neighborhood, covered by a log-polar window. Its bins uniformly partition the local neighborhood in log-polar space. For each bin, the grayness of the shape is accumulated and used as one component in the histogram. As the bins are uniform in log-polar space, the histogram is more sensitive to the positions of nearby points than to those farther away. Moreover, since only the sum of pixels within the same bin is relevant, it is inherently insensitive to small shape perturbations, which leads to its misalignment tolerance nature. In other words, the degree of misalignment tolerance is implicitly defined in the log-polar diagram. During the pixel summation, black pixel has a grayness of 1 while the white one Pis 0. The bin value of the k-th bin is computed as , where q is the position of the current pixel; is the relative position to the center of the log-polar window, returns the grayness at position q. The lower sub-image in Figure 6(a) visualizes the feature vector h with respect to p (the blue dot).
Transformation Awareness Unlike the original transformation-invariance scheme in [Mori et al. 2005], we propose a novel sampling layout of log-polar diagrams in order to account for the transformation difference. The log-polar histogram can natively account for orientation. The bin values change as the content rotates. To account for scaling, all log-polar histograms share the same scale. To account for translation (or position), N points are regularly sampled over the image in a grid layout (Figure 6(b)). Both the reference image in a cell and the character image are sampled with the same sampling pattern. For each sample point, a log-polar histogram is measured. The feature vectors (histograms) of the sample points are then concatenated to describe the shape, as shown in Figure 6(c). The shape similarity between two shapes, S and S 0 , is measured by comparing their feature vectors in a point-by-point basis, given by
Objective Function With the shape similarity and deformation metrics, the overall objective function can be defined. Given a particular text resolution, our optimization goal is to minimize the energy E,
where m is the total number of character cells, and K is the number of non-empty cells, and is used as the normalization factor. is the dissimilarity between the j-th cell’s content and its best-matched character, as defined in Equation 1. The term Ddeform is the deformation value of the j-th cell. When there is no deformation, ; hence E is purely dependent on . Note that the energy values of different text resolutions are directly comparable, as our energy function is normalized. The lower row of Figure 12 demonstrates such comparability by showing our results in three text resolutions along with their energies. The middle one (28×21) with the smallest energy corresponds to the most pleaant result, while the visually poor result on the left has a relatively larger energy.
We employ a simulated annealing strategy during the discrete optimization. In each iteration, we randomly select one vertex, and randomly displace its position with a distance of at most d. Here, d is the length of the longer side of the character image. Then, all affected grid cells due to this displacement are identified and best-matched with the character set again. If the recomputed E is reduced, the displacement is accepted. Otherwise, a transition probability is used to make the decision, where δ is the energy difference between two iterations; is the temperature; c is the iteration index; ta
is the initial average matching error of all grid cells. If Pr is smaller than a random number in [0, 1], this displacement is accepted; otherwise, it is rejected. The optimization is terminated whenever E is not reduced for co consecutive iterations, where in our implementation.
figure 10 shows the intermediate results along with their energies.
as the energy reduces, the visual quality of ascii art improves accordingly. an animated sequence for better visualization of such
optimization is included in the auxiliary material.
6 Results and Discussions
To validate our method, we conducted multiple experiments over a rich variety of inputs. the setting used for generating all our examples in this paper and their running times are listed in table 2. our method works with any font database of fixed character width. this paper shows results of matching characters from ascii code (95 printable characters) and shift-jis code (475 characters only). figures 14 to 17 show our results. the corresponding inputs can be found in figure 18. complete comparisons and results can be found in the auxiliary material.
Metrics Comparison In section 4, we have compared different shape similarity metrics for matching a single character. one may argue the visual importance of the proposed metric in generating the entire ascii art which may contain hundreds of characters. To validate its importance, we compare the ASCII art results (Figure 11) generated by substituting the character matching metric in our framework with different shape similarity metrics, including shape context, SSIM, RMSE after blurring and our metric. Hence, the same deformation mechanism is employed in generating all results. The result of shape context (Figure 11(a)) is most unrecognizable due to the structure discontinuity caused by the neglect of position. SSIM and RMSE preserve better structure as they place a high priority on position. Their alignment-sensitive nature, however, leads to the loss of fine details. Among all results, our metric generates the best approximation to the input, with the best preservation of structure and fine details. The comparison demonstrates the importance of transformation awareness and misalignment tolerance in preserving structure continuity and fine details.
Comparison to Existing Work Figure 2 already demonstrates the inferiority of the more naı̈ve halftoning approach in representing clear structure. The only alternative work that was tailormade for generating ASCII art is by O’Grady and Rickard [2008]. We therefore compare our results to those generated by their method in Figure 12(a). Due to its halftone nature, their method fails to produce satisfactory (in terms of structure preservation) results for all three text resolutions (from 18×13 to 35×28). All fine details are lost in their results.
User Study To conduct a user study, artists were invited to manually design ASCII art pieces for 3 test images. They were free to choose the desired text resolution for their pieces, but the character set was restricted to ASCII code. We then use our method and the method by O’Grady and Rickard to generate ASCII art results with the same text resolutions. Then, we invited 30 participants for the user study. The source image and three ASCII art results were shown side-by-side to the participants. Figure 13 shows our result as well as the artist piece from one of the 3 test sets. The complete set of comparison can be found in the auxiliary material. Each participant graded the ASCII art using 2 scores out of a 9-point scale ([1-9] with 9 being the best). The first score was to grade the similarity of the ASCII art pieces with respect to the input. The second was to grade the clarity of content presented in the ASCII art without referring to the input. Therefore, there were 18 data samples for analysis from each of the 30 participants. Altogether 540 data samples can be used for analysis.
From the statistics in Table 1, the results by O’Grady and Rickard are far from satisfactory in terms of both clarity and similarity. Our method is comparable to (but slightly poorer than) the artist production in terms of clarity. In terms of similarity, however, our method produced better results than the artist’s production. Such a phenomenon can be explained by that fact that artists can intelligently (creatively) modify or even drop parts of content in order to facilitate the ASCII approximation (e.g. hairstyle of the girl in Figure 13(b)). In some cases, they even change the aspect ratio of the input to facilitate character matching. On the other hand, our method respects the input aspect ratio and content.
Animated ASCII Art Figure 17 shows the ASCII art results of converting an animation to a sequence of ASCII art pieces. Although each frame is converted independently without explicit maintenance of temporal coherence, the generated ASCII art sequence is quite satisfactory. Readers are referred to the auxiliary material for a side-by-side comparison between the original frames and our generated ASCII art, in an animated fashion. Timing Performance The proposed system was implemented on a PC with 2GHz CPU, 8 GB system memory, and an nVidia Geforce GTX 280 GPU with 1G video memory. Table 2 summarizes the timing statistics of all examples shown in this paper. The second, third, and fourth columns show the corresponding text resolution, the character set used, and the running time for generating our ASCII art. The running time increases as the complexity of the input and the number of the characters increase.
Limitations Besides the fact that traditional ASCII art only works on a fixed-width font, modern ASCII art also deals with proportional fonts, e.g. Japanese Shift-JIS. Our current method does not handle proportional placement of characters or multiple font sizes in a single ASCII art piece. Another limitation is that we currently do not consider the temporal consistency when we generate the animation of ASCII art. To achieve this, one could first establish the correspondence between the shapes of the adjacent frames. Then one could constrain the deformation along the temporal dimension to achieve temporal consistency. Since our system only accepts vector input, real photographs or other raster images must first be converted into outline images. This could be done either by naı̈ve edge detection or a sophisticated line art generation method such as [Kang et al. 2007], followed by vectorization. This also means that our results would be affected by the quality of the vectorization. A poorly vectorized input containing messy edges would be faithfully represented by our system. One more limitation stems from the extremely limited variety of characters. Most font sets do not contain characters representing a rich variety of slopes of lines. This makes pictures such as radial patterns very hard to be faithfully represented.
7 Conclusion
In this paper, we present a method that mimics how ASCII artists generate structure-based ASCII art. To achieve this, we first propose a novel alignment-insensitive metric to account for position, orientation, scaling and shape. We demonstrate its effectiveness in balancing shape and transformations, comparing it to existing metrics. This metric should also benefit other practical applications requiring pattern recognition. Besides, a constrained deformation model is designed to mimic how the artists deform the input image. The rich variety of results shown demonstrates the effectiveness of our method. Although we have shown an application of animated ASCII art, its temporal consistency is not guaranteed. In the future, it is worth investigating the possibility of generating animations of ASCII art with high temporal consistency. An extension to proportional placement of characters is also worth studying. To further control and refine the result, it would also be beneficial to allow users to interactively highlight the important structure in the input for preservation during the deformation.
Acknowledgments
This project is supported by the Research Grants Council of the Hong Kong Special Administrative Region, under General Research Fund (CUHK417107). We would like to thank Xueting Liu for drawing some of the line art works, and ASCII artists on newsmth.net including Crowyue, Zeppeli, Wolfing, and Asan for
creating the ASCII arts in our comparison between the results by our method and by hand. Thanks also to all reviewers for their constructive comments and guidance in shaping this paper.
References
ARKIN , E. M., CHEW, L. P., HUTTENLOCHER , D. P., KEDEM, K., AND MITCHELL , J. S. B. 1991. An efficiently computable metric for comparing polygonal shapes. IEEE Trans. Pattern Anal. Mach. Intell. 13, 3, 209–216.
AU, D., 1995. Make a start in ASCII art. https://www.ludd.luth.se/~vk/pics/ascii/junkyard/techstuff/tutoals/DanielAu.html.
BAYER, B. 1973. An optimum method for two-level rendition of continuous-tone pictures. In IEEE International Conference on Communications, IEEE, (26–11)–(26–15).
BELONGIE, S., MALIK, J., AND PUZICHA, J. 2002. Shape matching and object recognition using shape contexts. IEEE Tran. Pattern Analysis and Machine Intelligience 24, 4, 509–522.
CJRANDALL, 2003. alt.ascii-art: Frequently asked questions. https://www.ascii-art.de/ascii/faq.html.
COHEN, I., AYACHE, N., AND SULGER, P. 1992. Tracking points on deformable objects using curvature information. In ECCV ‘92, Springer-Verlag, London, UK, 458–466.
CRAWFORD, R., 1994. ASCII graphics techniques v1.0. http://www.ludd.luth.se/~vk/pics/ascii/junkyard/techstuff/tutorials/RowanCrawford.html.
DAVIS, I. E., 1986. theDraw. TheSoft Programming Services.
DEFUSCO, R., 2007. MosASCII. freeware.
FLOYD, R. W., AND STEINBERG, L. 1974. An adaptive algorithm for spatial grey scale. In SID Int.Sym.Digest Tech.Papers, 36–37.
GAL, R., SORKINE, O., POPA, T., SHEFFER, A., AND COHENOR, D. 2007. 3d collage: Expressive non-realistic modeling. In In Proc. of 5th NPAR.
GEBHARD, M., 2009. JavE. freeware.
GOH, W.-B. 2008. Strategies for shape matching using skeletons. Comput. Vis. Image Underst. 110, 3, 326–345.
HSU, S.-C., AND WONG , T.-T. 1995. Simulating dust accumulation. IEEE Comput. Graph. Appl. 15, 1, 18–22.
KANG, H., LEE, S., AND CHUI, C. K. 2007. Coherent line drawing. In ACM Symposium on Non-Photorealistic Animation and Rendering (NPAR), 43–50.
KLOSE, L. A., AND MCINTOSH, F., 2000. Pictexter. AxiomX.
MILIOS, E. E. 1989. Shape matching using curvature processes. Comput. Vision Graph. Image Process. 47, 2, 203–226.
MILLER, G. 1994. Efficient algorithms for local and global accessibility shading. In Proceedings of SIGGRAPH 94, 319–326.
MORI, G., BELONGIE, S., AND MALIK, J. 2005. Efficient shape matching using shape contexts. IEEE Transactions on Pattern Analysis and Machine Intelligence 27, 11, 1832–1837.
O’G RADY, P. D., AND RICKARD, S. T. 2008. Automatic ASCII art conversion of binary images using non-negative constraints. In Proceedings of Signals and Systems Conference 2008 (ISSC 2008), 186–191.
SUNDAR, H., SILVER, D., G AGVANI, N., AND DICKINSON, S. 2003. Skeleton based shape matching and retrieval. SMI ‘03, 130.
TORSELLO, A., AND HANCOCK, E. R. 2004. A skeletal measure of 2d shape similarity. Computer Vision and Image Understanding 95, 1, 1–29.
ULICHNEY, R. A. MIT Press.
WAKENSHAW, H., 2000. Hayley Wakenshaw’s ASCII art tutorial. http://www.ludd.luth.se/~vk/pics/ascii/junkyard/techstuff/tutorials/HayleyWakenshaw.html.
WANG, Z., BOVIK, A. C., SHEIKH, H. R., MEMBER, S., SIMONCELLI , E. P., AND MEMBER, S. 2004. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing 13, 600–612.
WIKIPEDIA, 2009. ASCII art. https://en.wikipedia.org/wiki/Asciiart.
ZAHN, C. T., AND ROSKIES , R. Z. 1972. Fourier descriptors for plane closed curves. IEEE Tran. Computers 21, 3, 269–281.
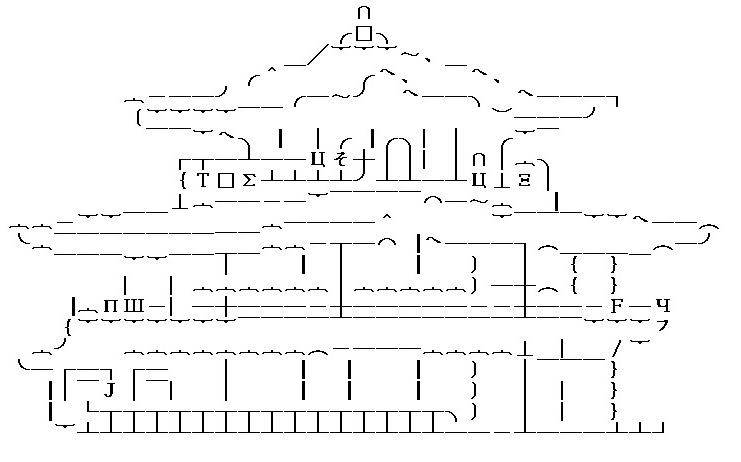
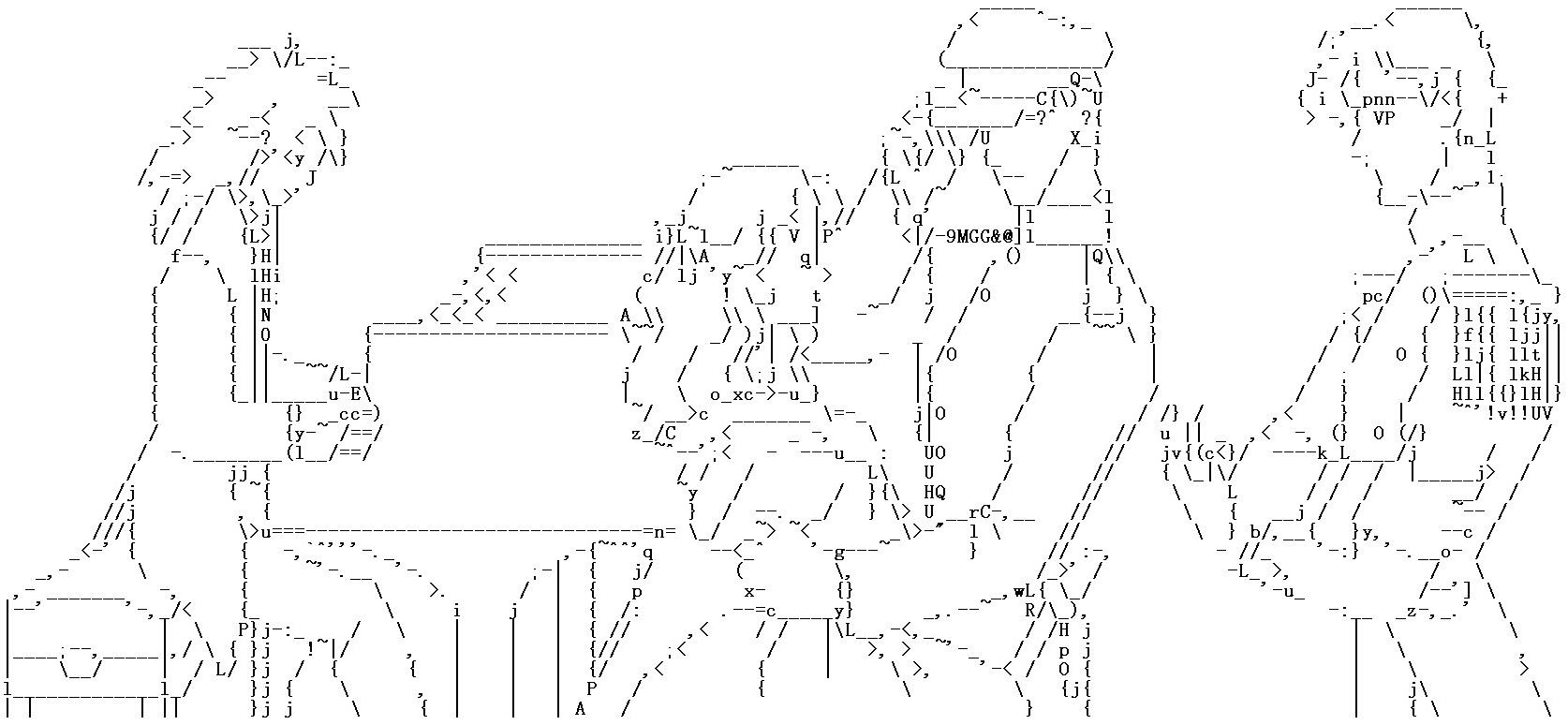
Figure 16: ASCII art of “train”
Figure 14: ASCII art of “dragon-man”


(a) Frame 1
(b) Frame 3 Figure 17: Animation of “toitorse”
(s3) “church”

Figure 18: Inputs of examples in this paper
(c) Frame 6
(s5) “train”
-
e-mail: xmxu@cse.cuhk.edu.hk ↩︎
-
e-mail: llzhang@cse.cuhk.edu.hk ↩︎
-
e-mail: ttwong@cse.cuhk.edu.hk ↩︎